Introducing Evaluator — AI at the Frontiers of Science & Technology
At Simple Machine Mind, we’ve built Evaluator: a multi-task, multi-class, multi-label model based on a BERT-base encoder, currently achieving a top F1 score of 82.4 with consistent reproducibility. The model is designed to arrive at a simple clinical-style decision at runtime—much like how humans decide on the spot—by simulating a cognitive judgment layer that can question, weigh options, and produce a decision under momentary policy settings.
Model scores (last validation epoch — 2025-08-18).
- Accuracy: 0.8506
- Mean F1: 0.8240
- Decision F1 (overall): 0.8240
- Emotion head — Precision / Recall / F1: 0.224 / 1.000 / 0.363
- Value head — Precision / Recall / F1: 0.279 / 1.000 / 0.412
- Class-wise Decision F1: [0.8321, 0.7564, 0.8834]
(Source: training logs; last completed epoch, best checkpoint saved.)
Disclaimer: Evaluator is an AI model and may make mistakes. Teams should follow standard development, testing, and deployment strategies for effective, safe use of the system.
How it works.
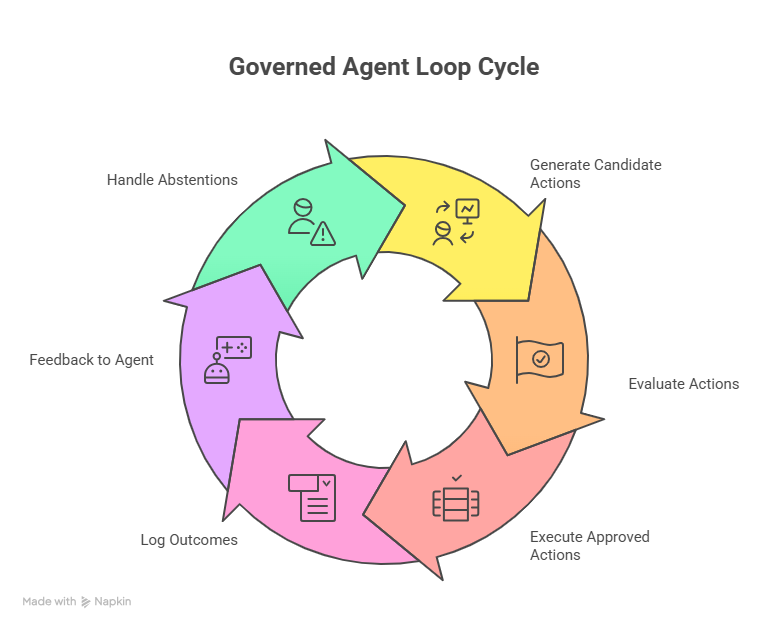
Evaluator takes short user context text as input (which can come from any AI or data-generating system) and pairs it with multi-hot policy vectors that represent requirements and constraints—what we call policy-as-code. For each input feature, the model returns a Yes / No / TBD decision class in one pass, using the provided policy to govern the outcome at inference time. The model treats the feature and its policy as immutable at inference, producing a deterministic feature state that is valid for that specific policy version active at that particular moment in time. This solves a small, focused decision problem that compounds into large organizational impacts.
Inputs & outputs (via API):
- Inputs: context text + policy vectors
- Outputs:
- A deterministic Yes/No/TBD decision class (with scores for all three classes, avoiding a brittle “winner-takes-all” effect).
- The policy vectors that supported the decision, enabling customers to adjust policies until the desired result is obtained—treating change as CI/CD, not a code rewrite.
Customers — Consumers & Developers.
- No ML expertise required: Organizations can use inference-only APIs to get decisions in minutes—no model development needed.
- Build your own intelligent systems: With the Developer Enterprise edition, teams can craft governed decision flows for KPIs, security, risk, compliance, FWA, and early-warning systems across technology, healthcare (decision support), engineering, and even boutique businesses.
A→B and B→A loops.
Evaluator can re-process its own outputs as inputs, enabling bidirectional A→B and B→A flows. This lets enterprises architect flexible pipelines aligned to their unique strengths and objectives.
Change management.
“By changing nothing, nothing changes.” Evaluator makes change safe: it will produce consistent results for the same policies, while also letting organizations version and adjust policies to measure effects before implementation—so teams can steer outcomes without risky code rewrites and supports low-code to no-code environments.
Infrastructure.
Evaluator runs on Microsoft Azure, a trusted, scalable cloud platform. It scales elastically with demand and is cost-efficient by design. Customers can purchase inference-only usage and scale up as needed. Microsoft Cloud also empowers small businesses to deploy enterprise-grade, high-end niche systems with built-in scalability and security—raising organizations of any size to best-in-class industry standards.
Data security.
By design, Evaluator does not store inference data, allowing adoption across regulated industries without exposing confidentiality, proprietary information, or sensitive data (PHI/PII/PCI). For Enterprise Developer licenses, opt-in logging can be enabled so the enterprise owns its data.
Security & Posture (Azure Front Door + APIM)
- Hardened edge with Azure Front Door (AFD): Global anycast edge, built-in WAF rules for common web exploits, rate limiting, and bot protections; TLS in transit end-to-end.
- API gateway control (APIM): Subscription keys/JWT enforcement, per-client quotas, IP allowlists, and request/response validation before traffic reaches app code.
- Least-privilege runtime: Container Apps run with managed identities; secrets stored in Key Vault; no inference data persisted by default.
- Private-by-default option: Ingress can be restricted to AFD/APIM; CORS and origin controls are explicit; audit logs available at the gateway.
- Policy-as-code alignment: The same policy objects that govern model decisions can also gate actions at the API layer (block, log, require human-in-the-loop), supporting a strong, “ready for consumption” posture.
Product Consumption Modes & Editions
- Configuration-first (most customers): Use the inference API with policy vectors—no ML expertise required. Most value comes from configuring policies and routing decisions into your workflows.
- Enterprise Developer edition (proposed; open weights subject to licensing): Option to train with your domain data for maximum domain fit while retaining explainability and policy governance.
- Fine-tuning & custom builds: Not provided out-of-the-box; for customers who need bespoke models, we offer consulting to develop in-house conditioned variants aligned to their data and controls.
Reducing LLM Inference Cost
Evaluator can plausibly act as a decision gate in front of LLMs to reduce unnecessary calls and context length:
- Smart routing: If the decision is Yes/No/TBD with high confidence, skip the LLM; only escalate low-confidence or novel cases.
- Prompt slimming: Convert noisy inputs into compact policy-conditioned features, reducing token usage when an LLM is still required.
- Deflect “expensive chatter”: Routine flows (e.g., apologies/thanks, confirmations, status checks) are handled deterministically—preventing the “sorry & thank you” spiral that racks up humongous LLM inference costs.
- Human-in-the-loop only when needed: Abstains auto-route to experts, keeping LLM + human bandwidth for the right cases.
“Abstain / TBD / I don’t know” — A First-Class Capability
- Safety over guesswork: The model can abstain when policy or evidence is insufficient, avoiding brittle forced decisions.
- Faster learning cycles: Abstains highlight unknowns with reasons, helping enterprises discover and resolve gaps to achieve better outcomes; teams can update policies and experiment before a successful rollout.
- Clean escalation: TBD routes to LLMs or humans with full context + policy, improving fix time and auditability.
- Better testing: During development, log and analyze abstains to close gaps; in production, monitor rates as a health signal for drift or new requirements.
- Philosophy of learning: “I don’t know” is the beginning of knowing—Evaluator encodes that humility so systems learn safely.
________________________________________
Congregation of Science and AI Technology
Evaluator is built for reproducibility: for a given input and policy version, it will return the same result, mirroring clinical decision patterns. In quantum physics, possibilities remain probabilistic until measurement yields a definite state. Evaluator plays a similar role in AI: under declared policies, it resolves probabilistic signals into determinate outcomes. Modern AI began by mimicking the brain’s architecture and later gained language as its medium for thought and communication, mirroring the knowledge path humans undertook from noise to words to language to stable knowledge. By using language as the engine of exploration and policy-as-code as the measurement apparatus, modern AI systems bring together insights from biology, computation, linguistics, and quantum reasoning into a single, governed AI system. The result is reproducible, auditable choices that move us from conventional AI toward well-governed, autonomous AGI on its accelerated path to ASI—where disciplines that once stood apart now work as one and complement one another.
AI and the Future of Science
AI is rapidly shaping the future of science by unifying exploration and judgment: generative models propose possibilities, while governed decision layers like Evaluator measure, select, or determine outcomes. LLMs Played a vital part in the development of Evaluator. Large language models (e.g., GPT-5 Thinking) acted as an exploration engine throughout Evaluator’s build—crucially—weigh the strategic merits and demerits of competing designs. cause of such Language systems, processed information is ready for quick digest for anyone , interested in exploratory science. AI now stands at the cusp of quantum physics, general relativity, and mystical science—where probabilistic phenomena, engineered systems, and human meaning intersect. By blending policy-as-code with explainable decisions, AI can evolve into Autonomous AGI—governed cognitive systems—turning unknowns into knowns and accelerating discovery.